Zookeeper 集群部署流程详解
ZooKeeper是一个开源的分布式应用程序协调服务,是Google的Chubby一个开源的实现。ZooKeeper为分布式应用提供一致性服务,提供的功能包括:分布式同步(Distributed Synchronization)、命名服务(Naming Service)、集群维护(Group Maintenance)、分布式锁(Distributed Lock)等,简化分布式应用协调及其管理的难度,提供高性能的分布式服务。
ZooKeeper本身可以以单机模式安装运行,不过它的长处在于通过分布式ZooKeeper集群(一个Leader,多个Follower),基于一定的策略来保证ZooKeeper集群的稳定性和可用性,从而实现分布式应用的可靠性。
1. 服务器环境准备
我们这次环境搭建,将采用5台主机来完成。其中两台主要用来做控制ZKFC(Zookeeper Failure Controller),另外三台作为客户端。
| 主机 | IP地址 | ZK | OS |
|---|---|---|---|
| master | 192.168.137.100 | CentOS7 | |
| secondary | 192.168.137.101 | CentOS7 | |
| slave1 | 192.168.137.102 | Y | CentOS7 |
| slave2 | 192.168.137.103 | Y | CentOS7 |
| slave3 | 192.168.137.104 | Y | CentOS7 |
1.1 关闭网络防火墙
为了保证系统能够正常运行,我们先关闭网络防火墙,在CentOS7下这样完成:
sudo systemctl stop firewalld sudo systemctl disable firewalld
1.2 关闭SELinux
SELinux也需要关闭,临时关闭采用这种:
sudo setenforce 0
永久关闭这样操作:
vi /etc/Selinux/config
将 SELINUX=行,修改为
SELINUX=disabled
1.3 设置主机名
在各台电脑上,分别编辑/etc/hostname,按照上述表格的主机名进行设置。
sudo vi /etc/hostname
138.137.100主机:
master
138.137.101主机:
secondary
138.137.102主机:
slave1
138.137.103主机:
slave2
138.137.104主机:
slave3
1.4 设置主机名称解析
再在各台主机上,编辑/etc/hosts文件:
sudo vi /etc/hosts
内容是一样的,均为:
192.168.137.100 master 192.168.137.101 secondary 192.168.137.102 slave1 192.168.137.103 slave2 192.168.137.104 slave3
1.5 创建相应的用户
为了方便,以后有关Hadoop、Zookeeper、Hive、HBase、Spark集群的安装,我们都将采用以下设置的账号和密码来进行。
useradd -m hadoop -G hadoop -s /bin/bash password hadoop
2. 安装配置Zookeeper
Zookeeper的官方网站为: http://zookeeper.apache.org。
大家可以去官网看看是否有新版本更新。
注意:
以下操作,将全部使用hadoop用户来完成。执行以下指令切换到hadoop用户:
su - hadoop
2.1 设置工作目录
执行以下指令,创建Zookeeper的程序和数据存放目录,并设置相应的权限。
sudo mkdir -p /opt/zookeeper sudo mkdir -p /home/hadoop/data/zookeeper/data sudo mkdir -p /home/hadoop/data/zookeeper/logs sudo chown -R hadoop:hadoop /opt/zookeeper sudo chown -R hadoop:hadoop /home/hadoop/data/zookeeper
2.2 下载
从国内镜像站点下载会快点:
wget http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz
2.3 解压
执行以下指令解压后,移动到刚才创建的工作目录。
tar zxvf zookeeper-3.4.13.tar.gz mv zookeeper-3.4.13/* /opt/zookeeper/
2.4 配置Zookeeper
执行以下指令编辑Zookeeper的配置文件:
cd /opt/zookeeper/conf cp zoo_sample.cfg zoo.cfg vi /opt/zookeeper/zoo.cfg
最后的内容如下:
# 服务器之间或客户端与服务器之间维持心跳的时间间隔
# tickTime以毫秒为单位。
tickTime=2000
# 集群中的follower服务器(F)与leader服务器(L)之间的初始连接心跳数
initLimit=10
# 集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数
syncLimit=5
# 快照保存目录
# 不要设置为/tmp,该目录重新启动后会被自动清除
dataDir=/home/hadoop/data/zookeeper/data
# 日志保存目录
dataLogDir=/home/hadoop/data/zookeeper/logs
# 客户端连接端口
clientPort=2181
# 客户端最大连接数。
# 根据自己实际情况设置,默认为60个
# maxClientCnxns=60
# 三个接点配置,格式为:
# server.服务编号=服务地址、LF通信端口、选举端口
server.1=salve1:2888:3888
server.2=slave2:2888:3888
server.3=slave3:2888:3888
将该文件分发到各个节点:
scp -R /opt/zookeeper/* secondary:/opt/zookeeper/ scp -R /opt/zookeeper/* slave1:/opt/zookeeper/ scp -R /opt/zookeeper/* slave2:/opt/zookeeper/ scp -R /opt/zookeeper/* slave2:/opt/zookeeper/
2.5 写入节点标记
在三个slave节点上,分别在/home/hadoop/data/zookeeper/data/myid写入节点标记:
slave1:
1
slave2:
2
slave3:
3
3. 启动Zookeeper
在slave1、slave2、slave3上,分别启动zkServer。
zkServer.sh start
4. 可用性测试
4.1 节点状态查看
在slave1、slave2、slave3上,分别执行以下指令看Zookeeper是否启动成功。
zkServer.sh status
可以看到,3个节点,一个leader,其他的都是follower。
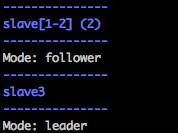
4.2 客户端连接测试
在客户端电脑上,执行以下指令测试连接:
# 连接服务器 [hadoop@master ~]$ zkCli.sh -server slave1:2181 # 查看目录 [zk: slave1(CONNECTED) 0] ls /